Abstract
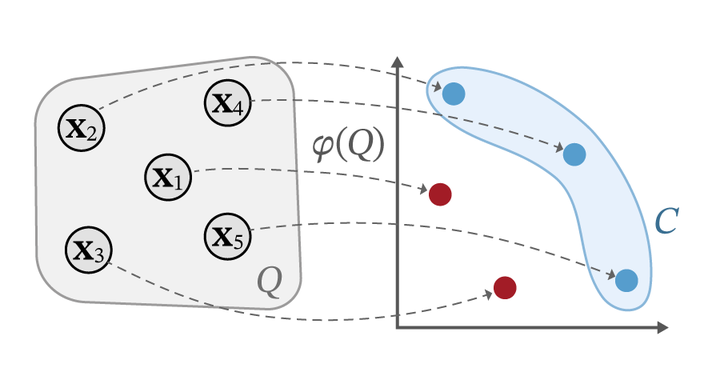
We consider the problem of learning to choose from a given set of objects, where each object is represented by a feature vector. Traditional approaches in choice modelling are mainly based on learning a latent, real-valued utility function, thereby inducing a linear order on choice alternatives. While this approach is suitable for discrete (top-1) choices, it is not straightforward how to use it for subset choices. Instead of mapping choice alternatives to the real number line, we propose to embed them into a higher-dimensional utility space, in which we identify choice sets with Pareto-optimal points. To this end, we propose a learning algorithm that minimizes a differentiable loss function suitable for this task. We demonstrate the feasibility of learning a Pareto-embedding on a suite of benchmark datasets.