Learning Choice Functions via Pareto-Embeddings
Abstract
We consider the problem of learning to choose from a given set of objects, where each object is represented by a feature vector. Traditional approaches in choice modelling are mainly based on learning a latent, real-valued utility function, thereby inducing a linear order on choice alternatives. While this approach is suitable for discrete (top-1) choices, it is not straightforward how to use it for subset choices. Instead of mapping choice alternatives to the real number line, we propose to embed them into a higher-dimensional utility space, in which we identify choice sets with Pareto-optimal points. To this end, we propose a learning algorithm that minimizes a differentiable loss function suitable for this task. We demonstrate the feasibility of learning a Pareto-embedding on a suite of benchmark datasets.
Virtual Poster
Introduction

Research Questions
- Can we generalize learning of a utility function that admits a natural choice function?
- Are we able to learn such a function from data?
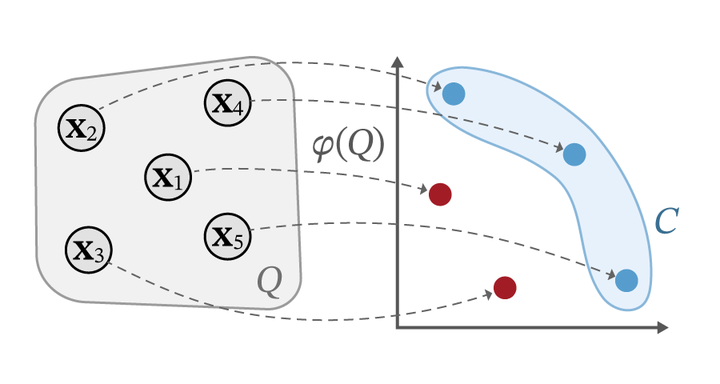
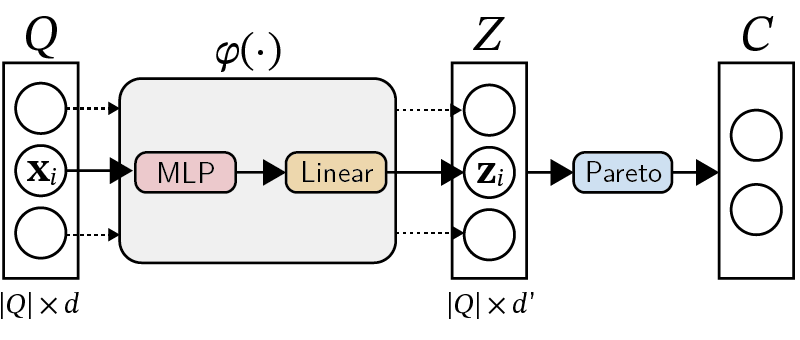
Pareto-Embeddings
Let $\mathcal{X} \subseteq \mathbb{R}^d$ be the set of objects. A set of objects $Q = {\mathbf{x}_1, \dots, \mathbf{x}_m}$ we call a query. A classical approach to model choices is to assume the existence of a utility function $\mathcal{X} \to \mathbb{R}$. A singular choice then arises naturally as picking the object with highest utility.

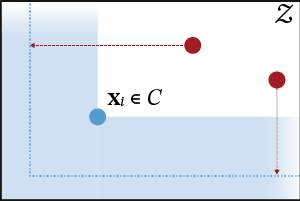
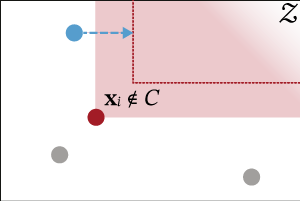
To induce a suitable embedding function $\varphi$ from data, we devise a differentiable loss function tailored to this task (see the paper for more details). The loss function consists of multiple terms of which the following two are the most important.
Results
We evaluate our approach on a suite of benchmark problems from the field of multi-criteria optimization. We use the well-known DTLZ and ZDT test suites, containing datasets of varying difficulty. Adding a simple two-dimensional two parabola (TP) dataset, we end up with 14 benchmark problems in total.
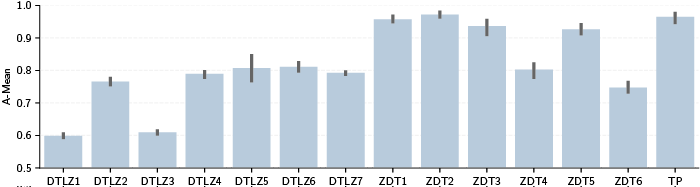
The results are shown in Figure 6. For five of the problems, the embedding approach is able to achieve an average A-mean of over 90%, indicating that for these problems we often identify the choice set correctly. This is important, as it shows that the loss function is able to steer the model parameters towards a valid Pareto-embedding. Thus, it is apparent that our learner is performing better than random guessing on all datasets.
Conclusion
- We proposed a novel way to tackle the problem of learning choice functions as an embedding problem.
- To learn an embedding from given data, we develop a suitable loss function that penalizes violations of the Pareto condition.
- The first results on benchmark problems are promising and we are looking forward to a more extensive empirical evaluation and applications to real-world choice problems.