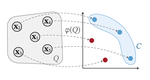
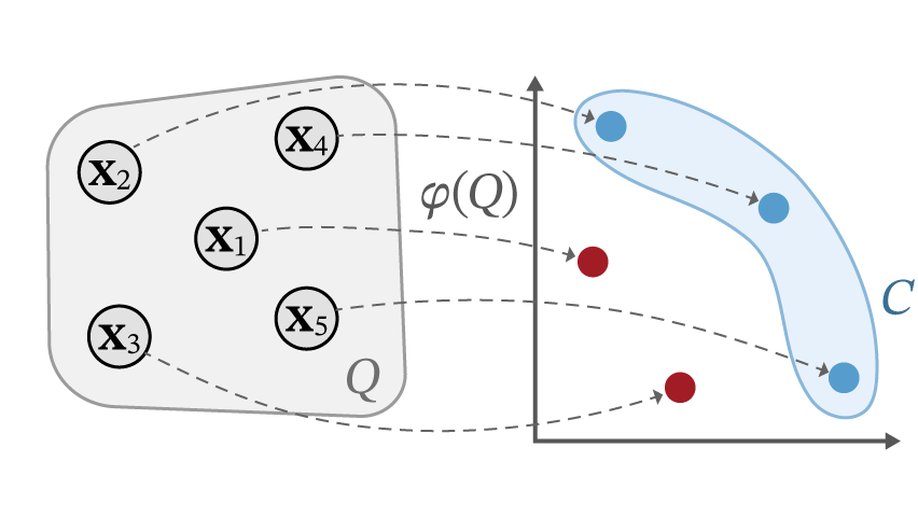
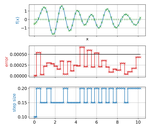
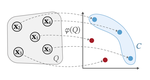
We study the problem of learning choice functions, which play an important role in various domains of application, most notably in the field of economics. Formally, a choice function is a mapping from sets to sets: Given a set of choice alternatives as input, a choice function identifies a subset of most preferred elements. Learning choice functions from suitable training data comes with a number of challenges. For example, the sets provided as input and the subsets produced as output can be of any size. Moreover, since the order in which alternatives are presented is irrelevant, a choice function should be symmetric. Perhaps most importantly, choice functions are naturally context-dependent, in the sense that the preference in favor of an alternative may depend on what other options are available. We formalize the problem of learning choice functions and present two general approaches based on two representations of context-dependent utility functions. Both approaches are instantiated by means of appropriate neural network architectures, and their performance is demonstrated on suitable benchmark tasks.